I am not a revenue manager. I am not a copywriter. I have never sat in a Booking.com extranet for a living, and the last time I read a paper on choice architecture I was probably procrastinating on something else. And yet, over a long weekend, I produced a 30-property merchandising audit of our entire Booking.com estate that reads like it came from a specialist agency — with a pricing-psychology rationale for every recommendation, a behavioural-economics gloss on rate plan structure, and a hotel-by-hotel comparison against the actual competitive set Booking.com puts us against.
I want to talk about how that happened, because I think it is the most important pattern I have seen in my career. It is not that I am cleverer than I was a year ago. It is that, for a smart and curious engineer, domain knowledge is no longer the moat. Claude Code, used well, will happily borrow expertise it does not have and apply it to data you supply, faster and more rigorously than most humans would. The bottleneck moves from "do I know this field?" to "do I know how to ask, and do I have the curiosity to keep pulling threads?"
What I actually built
The thing that exists at the end of the weekend is a self-contained static website you can hand to a non-technical executive. For each of our roughly 30 Staycity and Wilde properties on Booking.com, it shows:
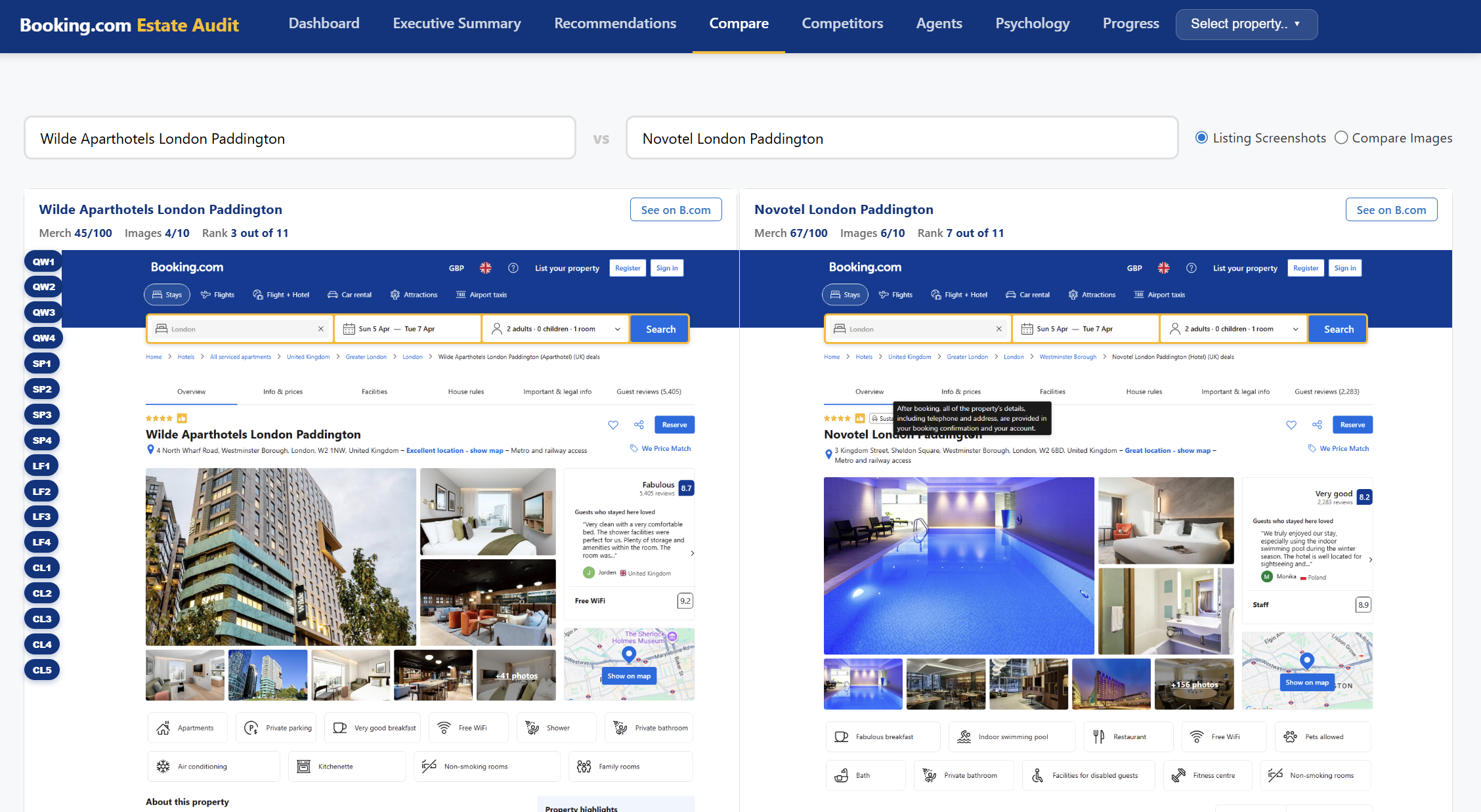
- A side-by-side visual comparison of our listing against every hotel in our Booking.com peer-comp set, full-page screenshots of the actual listings as they render today
- A scorecard across ten merchandising dimensions (photo sequence, pricing psychology, segment targeting, rate plan architecture, cancellation-policy framing, and so on)
- A prioritised recommendation list — Quick Wins, Strategic Priorities, Low-Hanging Fruit, Consider Later — with each item carrying an Impact × Effort tag, the specific extranet lever to pull, the time it takes, and the psychological rationale
- An estate-level executive narrative that pulls the cross-property themes together
Under the hood it is a pipeline of specialised Claude Code agents I designed for the job:
hotel-copy-analyst— reads descriptions across our hotel and its competitors and scores them on emotional tone, specificity, differentiator clarity, CTA effectiveness, amenity legibility and segment coverage. Knows the 1,000-character Booking.com limit.hotel-pricing-psychologist— applies a twelve-dimension behavioural-economics framework: anchoring, decoy pricing, struck-through prices, the contrast effect, payment coupling, choice overload, the compromise effect. It looks at our rate ladder as a guest would experience it on the page, not as a spreadsheet.hotel-image-analyst— multimodal, walks through every photo in the gallery, scores composition and emotional cues, judges the sequence as a narrative, identifies missing shots, recommends a new hero.hotel-cancellation-analyst— looks specifically at cancellation policy framing, the delta between refundable and non-refundable rates, and the commitment architecture that follows from it.hotel-benchmarker— synthesises the four specialists into cross-property scorecards and gap analysis.hotel-recommendation-engine— produces the final prioritised, lever-mapped action plan.booking-extranet-expert— annotates every recommendation with whether it is actually feasible to execute through the Booking.com extranet, and how long it takes.
That last agent matters more than it sounds. The whole audit is worthless if half the recommendations cannot be implemented in the tool the team actually uses on a Monday morning.
The kind of recommendation it produces
Here is the texture, taken from the audit of Wilde Paddington — at the time of writing, the worst-performing listing in its peer-comp set, ranked dead last on merchandising effectiveness despite holding an 8.7 review score and being the only true apartment product in a field of standard hotel rooms. (All the specific examples below were true on the day the audit ran. Our team moved fast on the Quick Wins and Strategic Priorities and most of these particular gaps have since been closed; I am leaving the original numbers in because the point of this post is the texture of the analysis, not the live state of any one listing.)
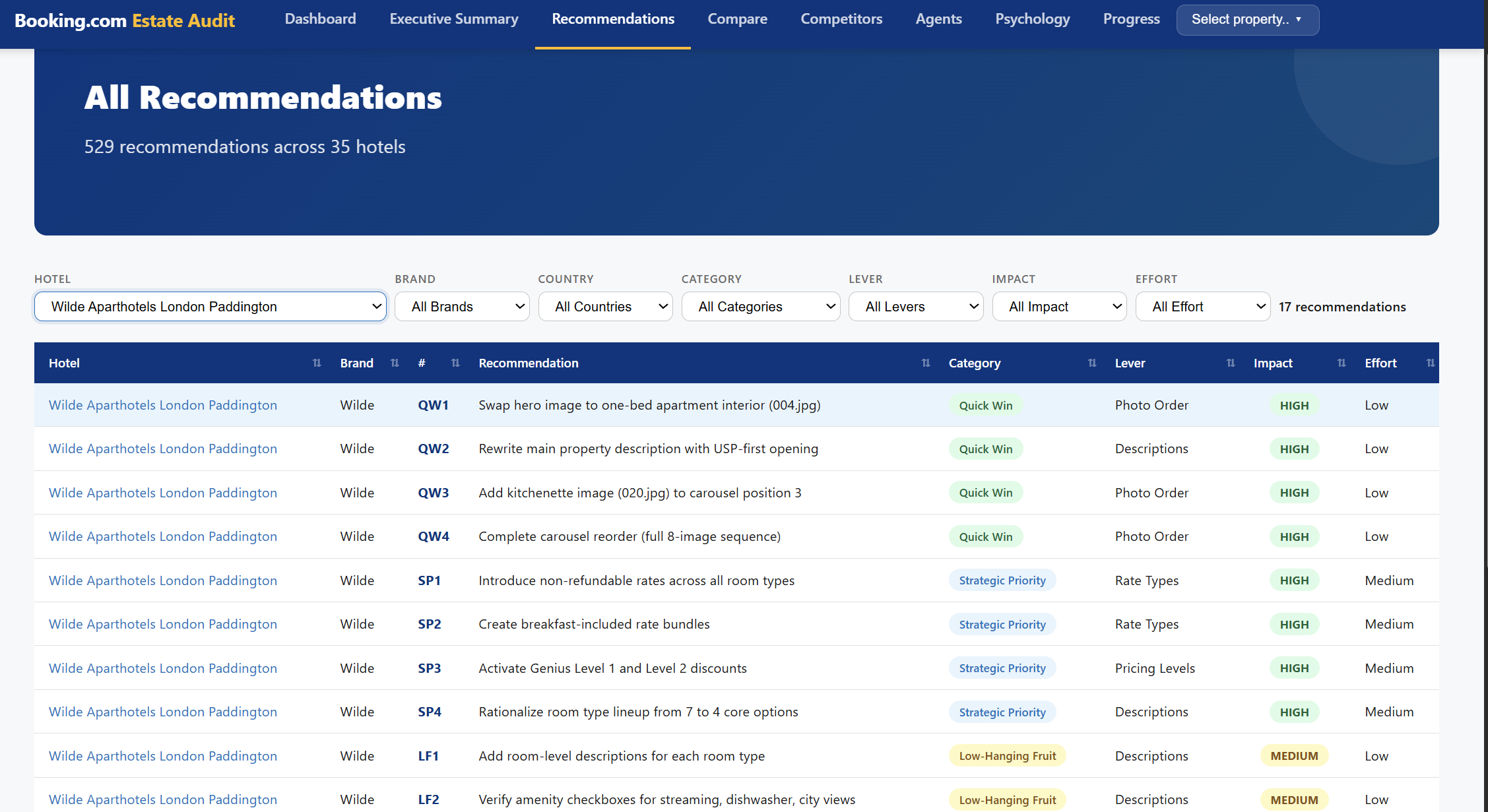
On images — the hero photo on the listing was an upward-angled shot of the building exterior; the agent flagged it as the weakest image in the carousel and recommended swapping in a one-bedroom apartment interior showing living area, bedroom and city view. It also noticed the kitchenette — the one feature no competitor in the Paddington set could offer — was buried at gallery position 20, invisible to mobile browsers who only see the carousel. The fix: drag it to position 3. Total time in the extranet: five minutes. Estimated impact: largest single zero-cost lever available.
On the gap between refundable and non-refundable rates — Wilde Paddington had zero non-refundable rates across six of its seven room types. Its entry price on a Booking.com search page therefore competed against Hilton Paddington at £366 NR, Novotel at £328 NR and voco at £237 NR — making Wilde appear 25–75% more expensive than it needed to be despite a better product and better reviews. The recommended fix: an "Advance Saver" non-refundable rate plan priced 10% below the current flex rate. For the base Studio that is £373 NR vs £414 flex. Two follow-on effects: the £41 gap reframes the flex rate as a small "insurance policy" for cancellation flexibility (the contrast effect), and non-refundable bookings carry sunk cost which reduces cancellation rate by an estimated 3–5 percentage points.
On rate architecture — the agent noticed Wilde was the only hotel in the entire 11-property set without breakfast-included rates, while every competitor offered a bundle. The remediation is not just "add breakfast"; it is to create a parallel set of rates so each room shows four rate plans rather than two, doubling the apparent depth of the offer and triggering the consideration-set psychology that makes a property feel established and confident.
On choice architecture — seven room types with overlapping names ("Studio", "Wilde Studio", "Wilde Studio Superior", "Superior Studio", two of those priced identically at £455 despite different square footage) created choice overload. The recommendation is a clean 4-tier ladder with a deliberate "compromise effect" middle option that the pricing structure quietly steers guests toward.
I want to be honest: I could not have written any of those paragraphs from scratch a year ago. I know what an aparthotel is. I know what Booking.com looks like. But the language of struck-through prices and compromise effects and decoy pricing and payment coupling is not mine. Or rather, it was not mine — until I sat down with an LLM that had read every relevant paper, and I had enough engineering instinct to give it the right data, the right structure, and the right adversarial reviewer to keep it honest.
Why "smart engineer plus LLM" is the new shape
I keep returning to the same thought. For most of my career, the way you scaled into a new domain was either to hire someone who already knew it, or to spend weeks reading until you knew enough to be dangerous. Both of those routes still exist. Both of them are now optional for a large class of problems.
A smart, curious engineer with Claude Code can:
- Decompose a fuzzy business question into specialist sub-problems (here: copy, pricing, images, cancellation, benchmarking, synthesis)
- Spin up a named expert for each sub-problem, with a tight prompt that forces it to cite a specific framework rather than wave its hands
- Wire those experts together into a pipeline with validation gates between phases — so if the pricing expert produces output the benchmarker cannot parse, the pipeline halts loudly rather than quietly degrading
- Apply that pipeline to real data, scraped from the actual surfaces customers see, rather than a sanitised abstract version
The output is not "what an LLM thinks about Booking.com listings in general". It is "what these eleven specific listings, with these specific photos and these specific rate ladders, look like when you grade them against the literature on choice architecture and the actual contents of the Booking.com extranet". That is something else entirely.
The gating skill is not domain knowledge. It is engineering taste — knowing how to slice a problem, where to put a validation step, when to insist on a counter-example, how to tell when an agent is bullshitting and how to make it stop.
What this means for the rest of us
There is an objection I hear constantly: but the LLM does not really understand pricing psychology, it is just pattern-matching. I think that is the wrong question. The right question is whether the recommendations it produces are correct, defensible and implementable on a Tuesday morning. In our case, every recommendation in the audit comes with a specific extranet lever, an estimated time-to-execute, a behavioural rationale, and an impact range — and our internal experts, when they review it, push back on roughly one item in fifteen. That is a far better hit rate than I get on most internal documents.
Which puts me in an awkward and energising position. The work that used to require a small specialist agency, six weeks and a five-figure invoice, I produced on a long weekend. Not because I am special. Because I was curious enough to push, and I had the tools to let the curiosity actually compound into output. The marginal cost of running it again next quarter, for a different segment, on a different OTA, is essentially zero.
If you are an engineer reading this and you have been holding back from a domain because "I don't know enough about it yet" — try the experiment. Pick the domain. Pick a real dataset. Pick the most expert-sounding question you can think of. Spend an afternoon decomposing it into specialists, give each specialist the data it needs, and force them to produce concrete, actionable, citable output. Then read what comes back.
I think you will find, as I did, that the moat you were respecting is mostly drawn on the map.